











目次
はじめに
こんにちは、半田(@handy)です。
AWS上でデータパイプラインを検討する際、よく見る構成としてはS3上のファイルをGlue Jobで変換した後、再度S3に格納してAthenaやRedshiftなどから参照する方法があります。
ただ、パフォーマンス要件からRedshiftにデータを取り込む必要がある場合、定期的にS3からのロードを行う必要があります。
今回の構成では途中に変換後用のS3を介することなく、Glue Jobから直接Redshiftにインサートを行うデータパイプラインを構築してみましたので、その構成や具体的な設定内容などについてご紹介します。
また、Glue Jobで変換する際、通常は一度S3に入れた変換前データをGlue Crawlerでクローリングし、メタデータをGlue DataCatalogに登録して、Glue DataCatalog経由でデータをロードする方法が取られることが多いかと思いますが、この方法ではGlue Crawlerで認識させるための変換処理前変換が必要になるケースがあります。
そのため、S3イベントとEventBridge Ruleを使用して、Glue JobでS3上の変換前データを直接取得して変換できるように構成しています。
※変換処理はGlue JobではなくLambdaでも問題ないのですが、データによっては15分制限がネックになるケースもあるため、今回はGlue Jobで実装してます。
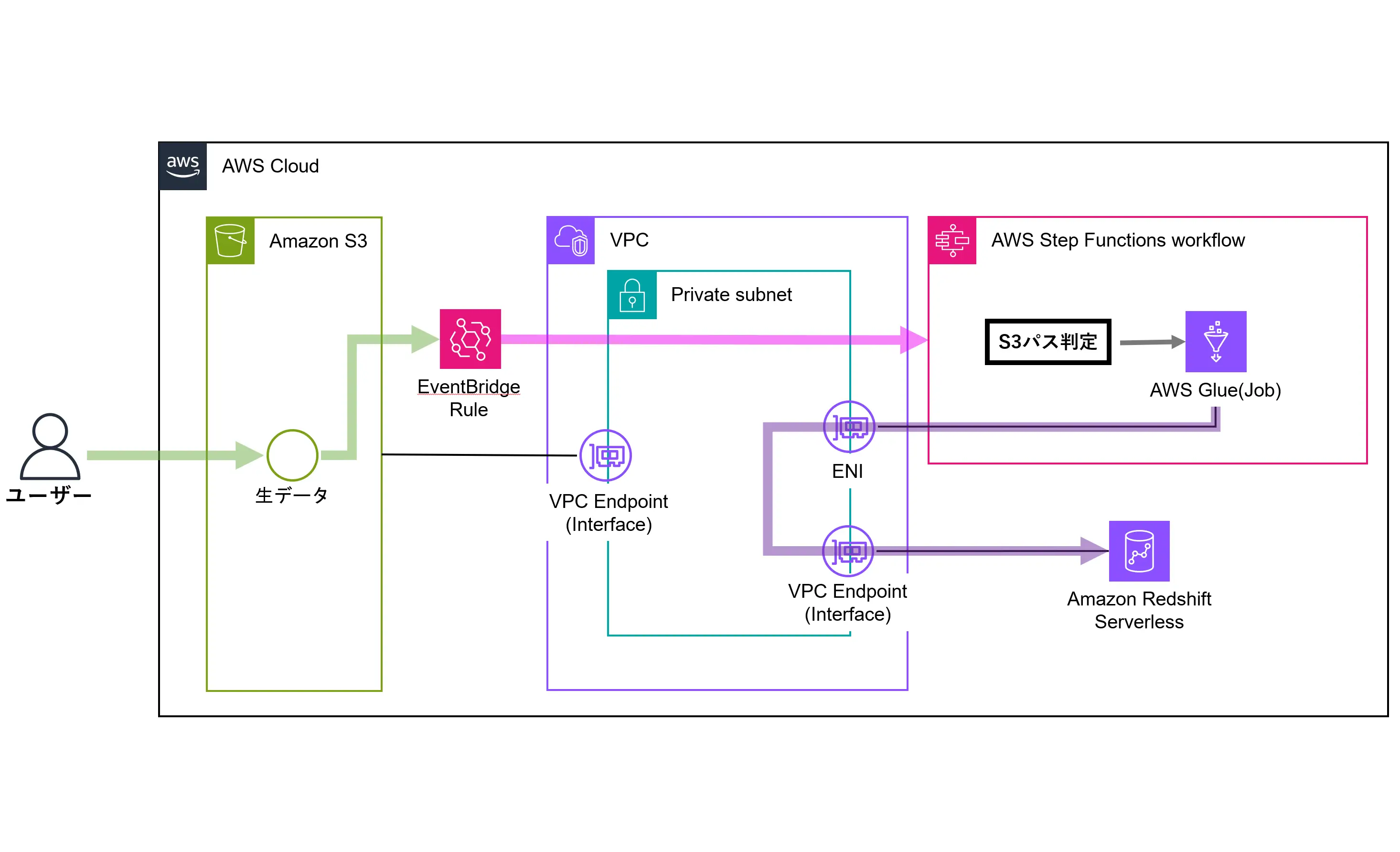
構築構成
今回構築したデータパイプラインは下記になります。
Glue Jobの実行はStepFunctionsから行うようにしており、S3パスで呼び出すGlue Jobを指定できるようにしています。(複数Jobへの対応を想定)
また、EventBridge Ruleから渡されたS3イベントデータをパラメータ経由でGlue Jobに渡し、Glue JobからはS3上の生データを直接読み込み・変換・インサートするようにしてます。
Redshift Serverlessはパブリックアクセス無しで構築しているため、Glue Connectionを使用してVPC Endpoint経由でRedshiftにアクセスさせるようにしました。
構築方法
今回はTerraformで構築しました。
下記GitHubで公開しているので、検証環境や前提条件を確認していただいた上でデプロイ手順を実施していただければ自環境でも同じものが構築できると思います。
前提
下記にTerraformを実行するのに必要な前提条件を記載します。
- 1つのVPCと3AZ分のSubnetが作成されていること
- ※恐らく「/27」のSubnetであれば問題ないと思います
- Terraform実行に必要なAWSアクセスキー、シークレットアクセスキーが作成されていること
- ※検証用環境を前提として、AdministratorAccess等の実行に必要な権限を付与してください
事前準備
Terraformは人によって使っているTerraformバージョンやAWSプロバイダーバージョンが異なる可能性が高いため、今回はDockerとaws-vaultを利用してローカルPC環境へのTerraformインストールを不要としました。
自環境で構築される際は、以下の2ツールがインストールされていなければ、事前にインストールしておいてください。
構築作業
構築手順はこちらに全て書いてあるので、具体的な手順はGitHubをご確認ください。
本記事ではリポジトリ内の一部の設定ファイルと設定項目について詳しく説明します。
リポジトリ構成
まずリポジトリ構成ですが、Terraformデプロイに必要なファイル・フォルダは全部で3種類あります。(デプロイに関係ない".gitignore"や"README.md"、"imgフォルダ"は除く)
それぞれの目的は以下になります。
- filesフォルダ :サンプルデータやTerraformで記述できないファイルを格納
- templateフォルダ :tfファイルやmodule群を格納
- docker-compose.yml:Terraformコマンド実行用のコンテナのための設定ファイル
./files
./img
./template
.gitignore
README.md
docker-compose.ymltemplateフォルダ構成
templateフォルダ配下はmodule群とデプロイ対象のtfファイルで構成されています。
わかりやすさ重視でサービスごとにファイルを分割しており、moduleは1つのtfファイルに書くと長くなる箇所だけ作成しました。
./modules
./modules/iam_policy/...
./modules/iam_role/...
./modules/securitygroup/...
.terraform.lock.hcl
data.tf
eventbridge.tf
glue_connection.tf
glue_job.tf
glue_job_sample_script.tf
iam_policy.tf
iam_role.tf
output.tf
providers.tf
redshift_serverless.tf
s3.tf
security_group.tf
step_gunctions.tf
variables.tf
vpc_endpoint.tf●variables.tf
本記事の前提にも絡むところですが、自分以外の環境でも実行できるようにVPC/Subnetは環境変数で指定できるようにしました。
実際のデプロイ時にはコンテナ上でTerraformコマンドが実行されるので、実行したターミナル上の環境変数をコンテナに渡せるように、docker-compose.ymlファイルのenvironmentに設定を追加してます。(後述します)
variable "vpc_id" {
description = "VPC ID"
type = string
}
variable "subnet_private_1a_id" {
description = "Subnet Private01a ID"
type = string
}
variable "subnet_private_1c_id" {
description = "Subnet Private01c ID"
type = string
}
variable "subnet_private_1d_id" {
description = "Subnet Private01d ID"
type = string
}●glue_job_sample_script.tf
TerraformでGlue Jobをデプロイする場合、事前にGlue Jobに指定するPythonファイルをS3上のスクリプト用バケットにアップロードしておく必要があります。
また、Glue Jobスクリプト内で使用するS3バケット名などを動的に設定したい場合は、事前に置換処理を行う必要もあります。
ここの処理ではその置換処理とS3アップロード処理を行っています。
# Glue Jobスクリプト内のS3バケット名を修正
resource "null_resource" "redshift_serverless_insert_job_s3_bucket" {
triggers = {
s3_bucket_name = aws_s3_bucket.glue_temp_bucket.bucket
}
provisioner "local-exec" {
command = "sed -i 's/__TEMP_S3_BUCKET_NAME__/${self.triggers.s3_bucket_name}/g' /files/python_script/${var.s3_glue_redshift_insert_job_script_file_name}"
}
depends_on = [
aws_s3_bucket.glue_temp_bucket
]
}
# Glue Jobスクリプト内のRedshift Connection名を修正
resource "null_resource" "redshift_serverless_insert_job_redshift_connection" {
triggers = {
redshift_connection_name = aws_glue_connection.redshift_serverless_connection.name
}
provisioner "local-exec" {
command = "sed -i 's/__REDSHIFT_CONNECTION_NAME__/${self.triggers.redshift_connection_name}/g' /files/python_script/${var.s3_glue_redshift_insert_job_script_file_name}"
}
depends_on = [
null_resource.redshift_serverless_insert_job_s3_bucket
]
}
# Glue Jobスクリプトアップロード
resource "aws_s3_object" "glue_script" {
bucket = aws_s3_bucket.glue_scripts_bucket.bucket
key = "scripts/${var.s3_glue_redshift_insert_job_script_file_name}"
source = "/files/python_script/${var.s3_glue_redshift_insert_job_script_file_name}"
depends_on = [
null_resource.redshift_serverless_insert_job_redshift_connection,
null_resource.redshift_serverless_insert_job_s3_bucket
]
}尚、その際にベースとなるスクリプトファイルはfilesフォルダ配下に格納しています。
●s3-glue-redshift-insert-job.py
スクリプトファイルは全量載せると少しボリュームがあるので、説明が必要な箇所だけ一部抜粋します。
以下の実装ではGlueのStartJob API実行時にStepFunctionsから渡されたS3パス情報を元にスクリプト側でファイルの取得処理を行っています。
# ジョブパラメーターを受け取る
args = getResolvedOptions(sys.argv, ['bucket', 'bucket_key'])
bucket = args['bucket']
bucket_key = args['bucket_key']
AmazonS3_node = glueContext.create_dynamic_frame.from_options(
format_options={"quoteChar": "\"", "withHeader": True, "separator": ",", "optimizePerformance": False},
connection_type="s3",
format="csv",
connection_options={
"paths": [f"s3://{bucket}/{bucket_key}"],
"recurse": True
},
transformation_ctx="AmazonS3_node"
)
Glue Jobを実装する場合はPyspark(Spark)で実装することになりますが、Pyspark(Spark)を使用した変換処理の実装は慣れるまで時間がかかります。
そこで、Glueバージョンの4.0を使用することで、SparkのPandas APIが利用した変換処理を実装することができます。
「.toPandas()」を利用するとSpark DataFrameからPandas DataFrameに変換ができるので、それ以降の変換処理をPandas DataFrameで行うことができます。
最後にGlue DynamicFrameに戻しているのは、後続処理でDynamicFrameを使用してRedshiftにインサートするためです。
import pyspark.pandas as ps
~省略~
# Convert Glue DynamicFrame to Spark DataFrame
spark_df = AmazonS3_node.toDF()
# Convert Spark DataFrame to Pandas DataFrame for transformation
pandas_df = spark_df.toPandas()
#==ここにpandasの処理を入れる==
# class_2y_string列を整数に変換して2倍にする
if 'class_2y_string' in pandas_df.columns:
pandas_df['class_2y_string'] = pandas_df['class_2y_string'].astype(int) * 2
~省略~
# データの先頭5行を出力
print("Data sample:")
print(pandas_df.head())
#==ここにpandasの処理を入れる==
# Convert Pandas DataFrame back to Spark DataFrame
modified_spark_df = spark.createDataFrame(pandas_df)
# Finally, convert Spark DataFrame back to Glue DynamicFrame
modified_dynamic_frame = DynamicFrame.fromDF(modified_spark_df, glueContext, "modified_df")
Glue DynamicFrameの「.write_dynamic_frame.from_options()」を利用してRedshiftへのインサート処理を行います。
「__TEMP_S3_BUCKET_NAME__」や「__REDSHIFT_CONNECTION_NAME__」はスクリプトファイルをS3にアップロードする際に正しいものに置換されます。
「preactions」パラメータはInsert処理前に実行されるSQLを指定することができ、今回は事前にテーブルがなければ作成するSQLを実装しています。
# Script generated for node Amazon Redshift
AmazonRedshift_node = glueContext.write_dynamic_frame.from_options(
frame=modified_dynamic_frame,
connection_type="redshift",
connection_options={
"redshiftTmpDir": "s3://__TEMP_S3_BUCKET_NAME__/redshift_temporary/",
"useConnectionProperties": "true",
"dbtable": "public.nursery_info",
"connectionName": "__REDSHIFT_CONNECTION_NAME__",
"preactions": """
CREATE TABLE IF NOT EXISTS public.nursery_info (
id BIGINT,
entity VARCHAR,
nursery_name VARCHAR,
~省略~
extended_age VARCHAR,
operator VARCHAR
);
"""
},
transformation_ctx="AmazonRedshift_node"
)
●step_functions.tf
StepFunctionsはS3パスの判別とGlue Jobの実行を行っているのですが、ステートマシンの記述部分は別のファイルで記述しており、Terraformでは"templatefile"を使って読み込みと置換を行っています。
## StepFunctions 定義
resource "aws_sfn_state_machine" "exec_glue_job_state_machine" {
name = var.aws_sfn_state_machine_name
role_arn = module.exec_glue_job_state_role.iam_role_arn
definition = templatefile(
"/files/sf_template/exec_glue_job_state.tftpl",
{
glue_job_name = aws_glue_job.redshift_serverless_insert_job.name
}
)
}尚、こちらもベースとなるテンプレートファイルはfilesフォルダ配下に格納しています。
以下が実際のテンプレートファイルになります。
Choicesステートで渡されたS3イベントパス内の文言とのマッチを確認し、一致したら「--bucket」と「--bucket_key」をパラメータにGlue Jobを実行するようになってます。
{
"Comment": "A description of my state machine",
"StartAt": "Choice",
"States": {
"Choice": {
"Type": "Choice",
"Choices": [
{
"Variable": "$.detail.object.key",
"StringMatches": "*sample_data_utf8*",
"Next": "RunGlueJob"
}
],
"Default": "Pass"
},
"RunGlueJob": {
"Type": "Task",
"Resource": "arn:aws:states:::glue:startJobRun",
"Parameters": {
"JobName": "${glue_job_name}",
"Arguments": {
"--bucket.$": "$.detail.bucket.name",
"--bucket_key.$": "$.detail.object.key"
}
},
"End": true
},
"Pass": {
"Type": "Pass",
"End": true
}
}
}●redshift_serverless.tf
Redshift ServerlessはこれまでSecrets Managerでのパスワード管理に対応していませんでしたが、2024年3月にアップデートがあり、現在では利用できるようになりました。
TerraformのAWSプロバイダーには5.39.0バージョンで追加されており、「manage_admin_password」パラメータを利用することでSecrets Managerを使用して管理パスワードが設定されるようになっています。
# Redshift Serverless 用 名前空間作成
resource "aws_redshiftserverless_namespace" "redshift_serverless_ns" {
namespace_name = var.aws_redshiftserverless_namespace_name
admin_username = var.aws_redshiftserverless_user_name
db_name = var.aws_redshiftserverless_db_name
manage_admin_password = true
iam_roles = [module.redshift_serverless_iam_role.iam_role_arn]
log_exports = ["userlog", "connectionlog", "useractivitylog"]
}
~省略~●glue_connection.tf
Redshift ServerlessのSecrets Manager対応に合わせて、Glue Connectionを指定する際は、以下のように"Data Souces"を使用して作成されたSecrets IDを指定する必要があります。
# Redshift Serverless用のSecrets Manager定義
data "aws_secretsmanager_secret" "redshift_serverless_secret" {
name = var.aws_secretsmanager_secret_name
depends_on = [
aws_redshiftserverless_namespace.redshift_serverless_ns,
aws_redshiftserverless_workgroup.redshift_serverless_wg,
]
}
# Redshift Serverless Connection定義
resource "aws_glue_connection" "redshift_serverless_connection" {
name = var.aws_glue_connection_redshift_serverless_connection_name
connection_type = "JDBC"
connection_properties = {
JDBC_CONNECTION_URL = "jdbc:redshift://${data.aws_redshiftserverless_workgroup.redshift_serverless_wg.endpoint[0].address}:${data.aws_redshiftserverless_workgroup.redshift_serverless_wg.endpoint[0].port}/${data.aws_redshiftserverless_namespace.redshift_serverless_ns.db_name}"
SECRET_ID = data.aws_secretsmanager_secret.redshift_serverless_secret.name
}
physical_connection_requirements {
availability_zone = "ap-northeast-1a"
security_group_id_list = [module.redshift_connection_sg.security_group_id]
subnet_id = var.subnet_private_1a_id
}
depends_on = [
aws_redshiftserverless_namespace.redshift_serverless_ns,
aws_redshiftserverless_workgroup.redshift_serverless_wg,
module.redshift_connection_sg.security_group_id,
]
}"Data Souces"に設定するSecrets名ですが、今回はvaliables.tfファイル内で固定名にしてますが、「redshift![名前空間名]-[DBユーザー名]」のフォーマットで作成されるようですので、必要に応じて動的に設定することとも可能です。
variable "aws_secretsmanager_secret_name" {
description = "Redshift Serverless用のSecrets Manager名"
type = string
default = "redshift!redshift-serverless-ns-admin"
}●vpc_endpoint.tf
また、今回はPrivate Subnet経由でGlue-Redshift Serverless間の通信を行うため、GlueからSecrets ManagerにアクセスするためのVPC Endpointを作成する必要もあります。
# SecretsManagerインターフェースエンドポイント作成
resource "aws_vpc_endpoint" "interface_secretsmanager" {
vpc_id = var.vpc_id
subnet_ids = [
var.subnet_private_1a_id,
]
service_name = "com.amazonaws.ap-northeast-1.secretsmanager"
vpc_endpoint_type = "Interface"
security_group_ids = [
module.secretsmanager_interface_endpoint_security_group.security_group_id
]
private_dns_enabled = true
tags = {
Name = "secretsmanager-interface-endpoint"
Env = "shared"
}
}docker-compose.ymlファイル内容
最後にdocker-compose.ymlファイルの内容は以下になります。
version: "3.7"
services:
terraform:
image: hashicorp/terraform:1.7.5
volumes:
- ./template:/template
- ./files/:/files
working_dir: /template
environment:
- AWS_ACCESS_KEY_ID=${AWS_ACCESS_KEY_ID}
- AWS_SECRET_ACCESS_KEY=${AWS_SECRET_ACCESS_KEY}
- AWS_SESSION_TOKEN=${AWS_SESSION_TOKEN}
- AWS_DEFAULT_REGION=${AWS_DEFAULT_REGION}
- TF_VAR_vpc_id=${vpc_id}
- TF_VAR_subnet_private_1a_id=${subnet_private_1a_id}
- TF_VAR_subnet_private_1c_id=${subnet_private_1c_id}
- TF_VAR_subnet_private_1d_id=${subnet_private_1d_id}特に見ていただきたいのはenvironmentです。
「AWS_~」から始まる箇所ではaws-vaultで設定された一時認証情報を渡すようにしており、VPC/SubnetのリソースIDは「TF_VAR_~」から始まる環境変数に渡すことでTerraform実行時に自動的に読み込まれるようにしました。
.envファイル等を作成しても良かったのですが、極力ファイルで管理する対象を増やしたくなかったので、このような構成となりました。
おわりに
実際に使う際はGlue Jobの管理とGlue Job以外のデータパイプライン全体の管理は分割したほうがわかりやすくなるかと思いますが、PoCレベルでとりあえず動くものを手早く作りたいというケースには使えるのではないかと思います。
あくまでサンプルのデータパイプライン構成となりますので、活用する際は実際の要件などに合わせて変更されるのが良いかと思います。
この記事がどなたかの参考になれば幸いです。

この記事をシェアする



