












目次
こんにちは。大友(@yomon8)です。
普段全くSAP触らないくせにSAPネタを連投します。
タイトルの通りHANA DBにPythonからSQLを投げ込んでデータを取得します。ただし、この方法は「技術的には可能」というだけで、本当にそれが必要なのか、ライセンス的に問題が無いのかは自身の環境毎にご確認ください。
当然、ここで私が使うのは検証用の環境となります。
ということで、昨日こちらの記事を書きましたが、ABAPインスタンス使いたかったわけでなく、HANAに繋いでみたかったからです。この検証環境を利用していきます。
コード
コードだけ最初にお伝えします。Python慣れている人なら記事見るまでもなく、コード見るだけで十分だと思います。devcontainerも準備してありますので、そのまま試してみることができます。
使い方ガイド
最初に以下の手順を実施します。
- git cloneでコードを取得
- devcontainer立ち上げ
- poetry installで必要なパッケージのインストール
ここまで完了しましたら、.envファイルを修正してください。
HDB_HOSTにはHANA DBのホスト名やIPアドレスを設定します。
HDB_PORTはHANAへの接続ポートなので、上記のDockerで立ち上げた環境の場合は30215ポートになります。
HDB_USERはSAP ABAPインスタンスで見えるテーブルをSELECTしたい場合はSAPA4Hを設定してください。
パスワードはコンテナのリンクに記載があります。
HDB_HOST="xxx.xxx.xxx.xxx"
HDB_PORT=30215
HDB_USER="SAPA4H"
HDB_PASSWORD="xxxx"SELECTしてみる
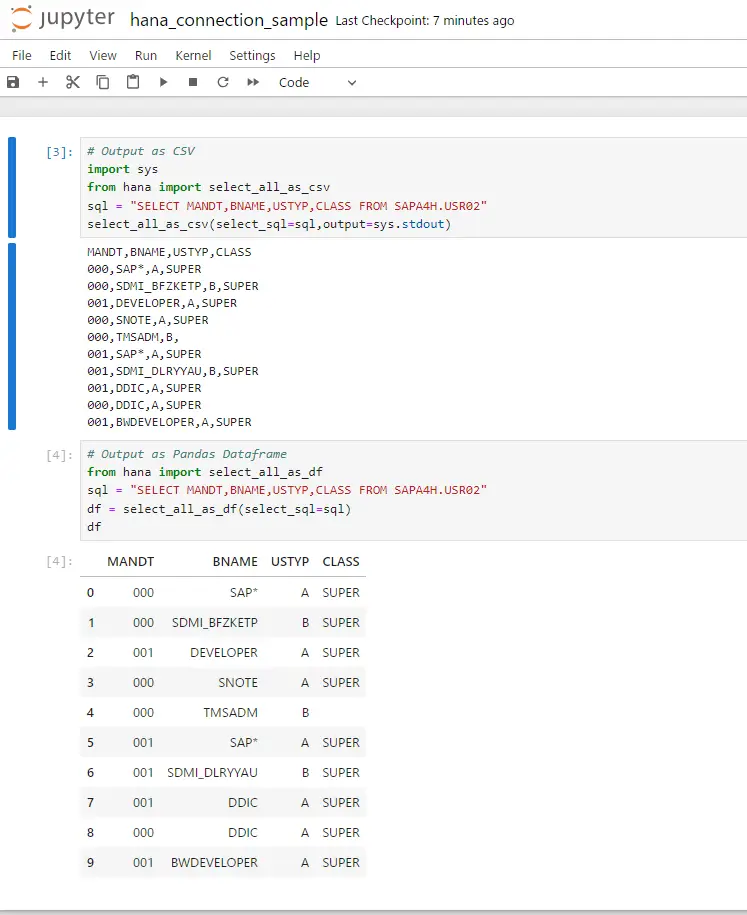
jupyter notebookから実行してみます。
hana_connection_sample.ipynbというNotebookファイルがありますので、こちらから実行してみます。
実行しているSQLは以下のSELECT文になります。
SELECT MANDT,BNAME,USTYP,CLASS FROM SAPA4H.USR02一つ目はCSV形式、二つ目はPandasのDataframe形式にフォーマットしてみました。データが取得できていることがわかると思います。
その他
実装は、こちらのヘルプに記載されているhdbcliというパッケージを使うことで可能になります。
使い方としては上記のSAP HELPの記事よりは、以下のpypiのページの方が詳しいので見ていただければと思います。他のDB接続系のパッケージを使ったことある方なら自然に使えるのではと思います。

Stubsも用意されているので、VSCodeなどを使うと開発しやすいと思います。
最後に
昔はSAP製品に繋ぐには技術的にも独自のものを利用することが多かった記憶があるので、HANAはDBとは言え、Pythonのパッケージを入れるだけで簡単に接続できたことに驚きました。
ただ、最初でも書いた通り、実際に本番で利用するにはライセンス、サポート、リスク等、検討しないといけない内容があると思います。あくまでただの技術検証の記事として見ていただければと思います。

この記事をシェアする



